发布时间:2025-06-10 阅读量:740 来源: 我爱方案网 作者:
【导读】英伟达近期优化了其产品路线图,进一步缩短了新一代AI芯片的研发周期。据行业消息,其下一代Rubin R100 GPU和Vera CPU预计最早将于2025年9月开始提供样品,目前已进入流片阶段。这一进展标志着英伟达在AI计算领域的持续领先地位,同时也反映了市场对高性能计算需求的快速增长。

Blackwell Ultra与Rubin间隔仅6个月,英伟达进入“超频”创新模式
此前,英伟达的产品迭代周期为“年度更新”,即每代架构间隔约12个月。然而,随着AI技术的迅猛发展,英伟达再次提速,Blackwell Ultra与Rubin之间的间隔预计仅为6个月。这一调整表明,英伟达正全力应对数据中心、大模型训练等领域的激烈竞争,确保其硬件始终处于行业最前沿。
Rubin R100 GPU:HBM4、3nm工艺与Chiplet设计带来革命性提升
Rubin R100 GPU将采用多项突破性技术,包括下一代HBM4高带宽内存,相比当前的HBM3E标准,带宽和能效均有显著提升。此外,该芯片将基于台积电的3nm(N3P)工艺制造,并采用CoWoS-L先进封装技术,进一步提升集成度和性能。
值得注意的是,Rubin R100还将首次采用Chiplet(小芯片)设计,这是英伟达在该领域的首次尝试。其芯片尺寸将达到4倍掩模大小(Blackwell为3.3倍),意味着更高的计算密度和更灵活的模块化架构。这一设计有望大幅提升AI训练和推理的效率,同时降低功耗。
Vera CPU接棒Grace,基于ARM下一代核心,性能大幅跃升
除了GPU的升级,英伟达还将推出新一代Vera系列CPU,取代现有的Grace系列。Vera CPU将基于ARM的下一代核心架构,预计在单核性能、多线程处理能力及能效比方面实现显著提升。结合Rubin GPU,英伟达的“CPU+GPU”组合将提供更强大的异构计算能力,适用于AI训练、高性能计算(HPC)和超大规模数据中心。
能效比成关键,英伟达推动绿色数据中心发展
随着AI算力需求的激增,数据中心的能耗问题日益突出。英伟达在Rubin架构上的核心目标之一就是优化性能功耗比,以降低运营成本并符合全球可持续发展趋势。通过采用更先进的制程工艺、HBM4内存和Chiplet设计,Rubin有望在提供更强算力的同时,减少单位计算任务的能耗。
Rubin/Vera组合将推动AI计算进入新纪元
Rubin GPU和Vera CPU的推出,标志着英伟达硬件堆栈的又一次重大升级。这一组合不仅将提升AI大模型训练、推理和科学计算的效率,还可能重塑数据中心的基础架构。随着9月流片日期的临近,行业正密切关注英伟达的下一步动向,以及其如何继续引领AI计算革命。

全球领先的传感器与功率IC解决方案供应商Allegro MicroSystems(纳斯达克:ALGM)于7月31日披露截至2025年6月27日的2025财年第一季度财务报告。数据显示,公司当季实现营业收入2.03亿美元,较去年同期大幅提升22%,创下历史同期新高。业绩增长主要源于电动汽车和工业两大核心板块的强劲需求,其中电动汽车相关产品销售额同比增长31%,工业及其他领域增速高达50%。
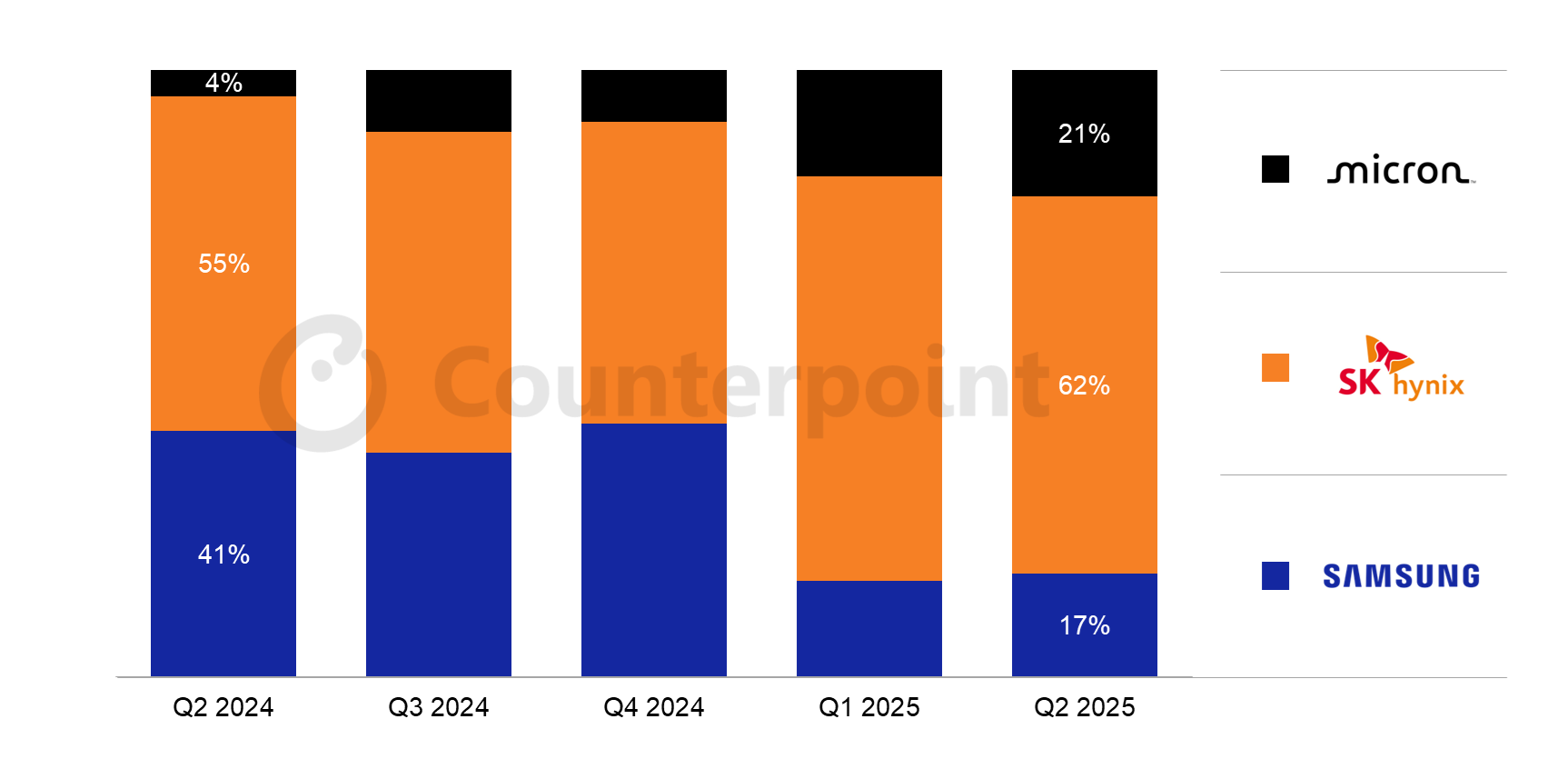
受强劲的人工智能(AI)需求驱动,全球存储芯片市场格局在2025年第二季度迎来历史性转折。韩国SK海力士凭借在高带宽存储器(HBM)领域的领先优势,首次超越三星电子,以21.8万亿韩元的存储业务营收问鼎全球最大存储器制造商。三星同期存储业务营收为21.2万亿韩元,同比下滑3%,退居次席。

8月1日,英伟达官网更新其800V高压直流(HVDC)电源架构关键合作伙伴名录,中国氮化镓(GaN)技术领军企业英诺赛科(Innoscience)赫然在列。英诺赛科将为英伟达革命性的Kyber机架系统提供全链路氮化镓电源解决方案,成为该名单中唯一入选的中国本土供应商。此重大突破性合作直接推动英诺赛科港股股价在消息公布当日一度飙升近64%,市场反响热烈。

全球领先的功率半导体解决方案供应商MPS(Monolithic Power Systems)于7月31日正式公布截至2025年6月30日的第二季度财务报告。数据显示,公司本季度业绩表现亮眼,多项核心指标实现显著增长,并释放出持续向好的发展信号。

贸泽电子(Mouser Electronics)于2025年8月正式推出工业自动化资源中心,为工程技术人员提供前沿技术洞察与解决方案库。该平台整合了控制系统、机器人技术及自动化软件的最新进展,旨在推动制造业向智能化、可持续化方向转型。



