发布时间:2022-12-2 阅读量:1097 来源: 我爱方案网整理 发布人: Aurora
Amazon Web Services已经表明,云计算的未来不能仅依靠其新型Graviton3E芯片的通用芯片,AWS将与AMD和英特尔一起推出旨在更快、更高效地执行某些应用程序的专用中央处理器。
虽然受益于许多并行工作的内核,计算世界越来越多地开始使用GPU来处理AI训练等工作负载,但英特尔、AMD和AWS发现为一些对企业、政府、政府和组织都很重要的数据密集型应用程序定制CPU的好处。
这意味着未来CPU改进的节奏不会那么简单,因为这三家公司很快都会有通用和专用的中央处理器可用。对于具有高性能需求的组织,这将需要对系统配置进行更多审查,因为芯片设计人员希望以新的方式提高性能和效率。
就Gravtion3E而言,AWS、AMD和英特尔最近和即将推出的CPU有着相同的目标——高性能计算——至少在更广泛的层面上是这样。我们谈论的是科学家、工程师和其他数据相关专业人士使用的广泛应用,例如计算流体动力学、天气建模和分子动力学等。
AWS本周表示,Graviton3E非常适合HPC应用程序,因为它针对浮点和矢量数学进行了优化。AWS执行官Peter DeSantis声称,与今年早些时候开始为实例提供动力的通用Graviton3相比,这种微调使基于Arm的芯片在生命科学和金融建模工作负载的基准测试中运行得更快。

虽然AWS没有透露有关Graviton3E的许多细节,但我们可以看看来自AMD和英特尔的新的HPC调优CPU,以了解如何调整通用芯片以使一组应用程序受益。
AMD提升缓存以服务于技术计算应用程序
今年早些时候,AMD推出了一款全新的Epyc服务器芯片,代号为Milan-X,旨在加速HPC中的应用程序。目标工作包括电子设计自动化、计算流体力学、有限元分析和结构分析模拟,AMD将其置于“技术计算”的保护伞之下。
Milan-X芯片的批量定价比普通的具有类似特性的第三代Epyc处理器“略有溢价”,但AMD表示,由于CPU上融合了大量缓存,用户可以期待目标工作负载的性能大幅提升。额外的性能以768MB的L3高速缓存的形式出现,是2021年推出的通用第三代通用Epycs的三倍。这意味着双插槽服务器的L3缓存总量可以超过1.5GB。
扩大的L3高速缓存允许CPU在靠近处理器核心的地方存储更多的数据,这对于经常移动大量数据的技术计算工作负载非常重要。AMD声称16核Milan-X芯片每小时可以为Synopsys用于芯片设计的VCS软件执行40.6个任务。相比之下,AMD的同一代16核Epyc每小时只能完成24.4个任务,使得Milan-X芯片的速度提高了66%。
该公司还声称,Milan-X的运行速度比英特尔去年推出的第三代至强可扩展芯片快23-88%,适用于各种技术计算应用。
英特尔通过高带宽内存应对HPC
英特尔还在解决让更多数据更靠近HPC应用程序内核的问题,除了没有创建更大的缓存,该公司还设计了一款具有64GB高带宽内存的CPU。这是指英特尔即将推出的XeonMax系列处理器,它们是明年初推出的SapphireRapids服务器芯片的HPC变体。
英特尔表示,至强Max芯片的性能将优于其第三代至强可扩展处理器和AMD的Milan-X芯片,适用于广泛的HPC应用程序。它通过展示近20个HPC基准来做出这一声明,最高的XeonMax芯片的性能比上一代处理器高出20%至近5倍。
通过将64 GB的高带宽内存直接放入芯片中,英特尔在服务器配置方式上也提供了更大的灵活性。例如,数据中心操作员只需依赖XeonMax的高带宽内存,就可以完全放弃服务器中的DRAM,而无需进行代码更改。这反过来又有望降低购买内存DIMM及其能源成本的相关成本。
XeonMax还可以与高带宽内存一起使用DRAM来扩展整个系统的内存,尽管这需要在软件中进行代码更改。或者,用户可以配置XeonMax的高带宽作为DDR的缓存,而DDR不需要任何代码更改。
虽然增加的高带宽内存是XeonMax的决定性特性,但处理器还有其他的功能来增强某些HPC和AI应用,如英特尔深度学习助推器、英特尔数据流加速器和英特尔高级矩阵扩展。
碎片化处理的未来
专用CPU并不是全新的概念。英特尔一直在大量生产针对电信工作负载进行优化的至强处理器。但这批新产品代表了一个更大的浪潮,即将到来的中央处理器将不会被设计为服务于尽可能广泛的应用程序。
英伟达(Nvidia)计划在明年年初发布基于ARM的Grace CPU,用于HPC和人工智能。另一方面,AMD正在开发未来几代Epyc芯片,这些芯片不仅针对HPC进行了优化,还针对边缘和电信工作负载进行了优化。英特尔和AMD都在开发为云计算优化的CPU。
我们需要考虑英特尔、Nvidia和AMD正在研究如何让CPU和GPU之间的距离更近一些,用于需要大量马力的应用程序。对于英伟达来说,这将在明年以Grace Hopper Superchip的形式出现。英特尔计划在2024年通过其Falcon Shores"XPU"实现这一目标。与此同时,AMD打算在明年推出的Instinct MI300芯片上实现这一点。
关于我爱方案网
我爱方案网是一个电子方案开发供应链平台,提供从找方案到研发采购的全链条服务。找方案,上我爱方案网!在方案超市找到合适的方案就可以直接买,没有找到就到快包定制开发。我爱方案网积累了一大批方案商和企业开发资源,能提供标准的模块和核心板以及定制开发服务,按要求交付PCBA、整机产品、软件或IoT系统。更多信息,敬请访问http://www.52solution.com

英伟达正式发布代号“Rubin CPX” GPU产品,专为AI领域最棘手的“大规模上下文推理”而生。

9月10日,SEMI-e深圳国际半导体展暨2025集成电路产业创新展在深圳国际会展中心盛大启幕。本届展会由CIOE中国光博会与集成电路产业技术创新联盟(简称“大联盟”)共同主办,规模与影响力显著提升,汇聚全球半导体行业顶尖企业、专家学者与产业链关键代表,聚焦光电融合、先进制造与跨领域协同,全方位呈现集成电路与光电子技术的最新成果与发展趋势,为产业创新与合作搭建起高规格、高效率的国际性平台。
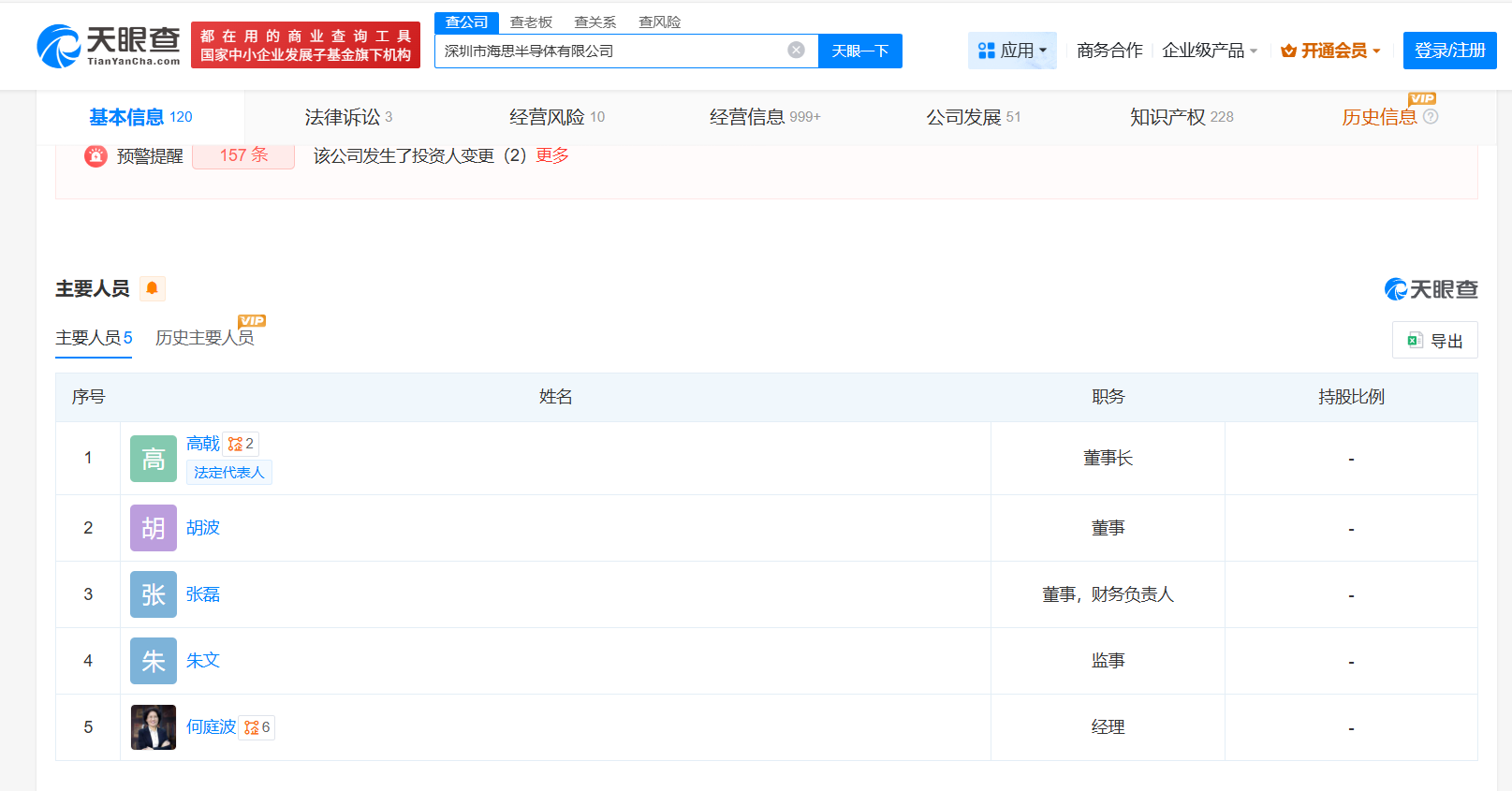
华为旗下核心芯片设计公司深圳市海思半导体有限公司完成重大人事调整,徐直军卸任法定代表人、董事长,由技术背景深厚的高戟接棒,同时完成多位高管的更迭

美国联邦通信委员会(FCC)发布通告:“基于国家安全考量”,FCC即刻实施新规,撤销或拒绝由“外国对手”控制的测试实验室的FCC认证资格

为精准锚定行业需求、高效整合产业资源,全力备战2025年11月5–7日在上海新国际博览中心举办的第106届中国电子展,中国电子展组委会与电子制造产业联盟联合组建专项调研团队,于近期跨越广东、湖南、湖北三省,深入深圳、东莞、长沙、武汉四地,开展了一系列高密度、深层次的企业走访与产业对接活动。通过实地考察和多轮座谈,调研团队系统梳理了华南、华中地区电子制造产业链资源,为展会的高水平举办奠定了扎实基础。



