发布时间:2022-05-19 阅读量:27618 来源: 我爱方案网 作者:
本篇测评由电子工程世界的优秀测评者“流行科技”提供。
此次测试的开源项目,是基于QT+OpenCV的人脸识别打卡项目。本次体验使用的是开源的代码,此代码本来是运行在WIN下的,为了测试稍微进行了修改,让其运行在米尔iMX8M Plus开发板上。

测试项目实际是分了两个工程,一个工程是作为管理员控制功能使用,添加人脸信息。同时也可以查询到打卡记录,对从机进行下发通知等等。
人脸识别我们主要需要用到opencv的人脸检测分类器。

OpenCV编译完成后已经提供好了的。
因为这里还需要涉及到训练模型,有了模型后才能更好地识别,所以还是简单介绍下怎么训练的吧。
CascadeClassifier cascada;
//将opencv官方训练好的人脸识别分类器拷贝到自己的工程目录中
cascada.load("F:videoccchaarcascade_frontalface_alt2.xml");
VideoCapture cap(1); //0表示电脑自带的,如果用一个外接摄像头,将0变成1
Mat frame, myFace;
int pic_num = 1;
while (1) {
//摄像头读图像
cap >> frame;
vector
Mat frame_gray;
cvtColor(frame, frame_gray, COLOR_BGR2GRAY);//转灰度化,减少运算
cascada.detectMultiScale(frame_gray, faces, 1.1, 4, CV_HAAR_DO_ROUGH_SEARCH, Size(70, 70), Size(1000, 1000));
printf("检测到人脸个数:%dn", faces.size());
//识别到的脸用矩形圈出
for (int i = 0; i < faces.size(); i++)
{
rectangle(frame, faces, Scalar(255, 0, 0), 2, 8, 0);
}
//当只有一个人脸时,开始拍照
if (faces.size() == 1)
{
Mat faceROI = frame_gray(faces[0]);//在灰度图中将圈出的脸所在区域裁剪出
//cout << faces[0].x << endl;//测试下face[0].x
resize(faceROI, myFace, Size(92, 112));//将兴趣域size为92*112
putText(frame, to_string(pic_num), faces[0].tl(), 3, 1.2, (0, 0, 225), 2, 0);//在 faces[0].tl()的左上角上面写序号
string filename = format("F:video%d.jpg", pic_num); //图片的存放位置,frmat的用法跟QString差不多
imwrite(filename, myFace);//存在当前目录下
imshow(filename, myFace);//显示下size后的脸
waitKey(500);//等待500us
destroyWindow(filename);//:销毁指定的窗口
pic_num++;//序号加1
if (pic_num == 11)
{
return 0;//当序号为11时退出循环,一共拍10张照片
}
}
int c = waitKey(10);
if ((char)c == 27) { break; } //10us内输入esc则退出循环
imshow("frame", frame);//显示视频流
waitKey(100);//等待100us
}
return 0;
通过上面的代码,完成图像采集。
//读取你的CSV文件路径.
//string fn_csv = string(argv[1]);
string fn_csv = "F:videocccat.txt";
// 2个容器来存放图像数据和对应的标签
vector
vector
// 读取数据. 如果文件不合法就会出错
// 输入的文件名已经有了.
try
{
read_csv(fn_csv, images, labels); //从csv文件中批量读取训练数据
}
catch (cv::Exception& e)
{
cerr << "Error opening file "" << fn_csv << "". Reason: " << e.msg << endl;
// 文件有问题,我们啥也做不了了,退出了
exit(1);
}
// 如果没有读取到足够图片,也退出.
if (images.size() <= 1) {
string error_message = "This demo needs at least 2 images to work. Please add more images to your data set!";
CV_Error(CV_StsError, error_message);
}
for (int i = 0; i < images.size(); i++)
{
//cout< if (images.size() != Size(92, 112)) { cout << i << endl; cout << images.size() << endl; } } // 下面的几行代码仅仅是从你的数据集中移除最后一张图片,作为测试图片 //[gm:自然这里需要根据自己的需要修改,他这里简化了很多问题] Mat testSample = images[images.size() - 1]; int testLabel = labels[labels.size() - 1]; images.pop_back();//删除最后一张照片,此照片作为测试图片 labels.pop_back();//删除最有一张照片的labels // 下面几行创建了一个特征脸模型用于人脸识别, // 通过CSV文件读取的图像和标签训练它。 // T这里是一个完整的PCA变换 //如果你只想保留10个主成分,使用如下代码 // cv::createEigenFaceRecognizer(10); // // 如果你还希望使用置信度阈值来初始化,使用以下语句: // cv::createEigenFaceRecognizer(10, 123.0); // // 如果你使用所有特征并且使用一个阈值,使用以下语句: // cv::createEigenFaceRecognizer(0, 123.0); //创建一个PCA人脸分类器,暂时命名为model吧,创建完成后 //调用其中的成员函数train()来完成分类器的训练 Ptr model->train(images, labels); model->save("MyFacePCAModel.xml");//保存路径可自己设置,但注意用“” Ptr model1->train(images, labels); model1->save("MyFaceFisherModel.xml"); Ptr model2->train(images, labels); model2->save("MyFaceLBPHModel.xml"); // 下面对测试图像进行预测,predictedLabel是预测标签结果 //注意predict()入口参数必须为单通道灰度图像,如果图像类型不符,需要先进行转换 //predict()函数返回一个整形变量作为识别标签 int predictedLabel = model->predict(testSample);//加载分类器 int predictedLabel1 = model1->predict(testSample); int predictedLabel2 = model2->predict(testSample); // 还有一种调用方式,可以获取结果同时得到阈值: // int predictedLabel = -1; // double confidence = 0.0; // model->predict(testSample, predictedLabel, confidence); string result_message = format("Predicted class = %d / Actual class = %d.", predictedLabel, testLabel); string result_message1 = format("Predicted class = %d / Actual class = %d.", predictedLabel1, testLabel); string result_message2 = format("Predicted class = %d / Actual class = %d.", predictedLabel2, testLabel); cout << result_message << endl; cout << result_message1 << endl; cout << result_message2 << endl; getchar(); //waitKey(0); return 0; 通过上面的代码进行训练,训练使用了python。所以系统环境需要配置好。 在此文件中,把我们采集到的图像,放进去,新建一个文件夹。 之后就是把我们的at.txt也加入我们的文件。 训练好后,我们就得到了我们所需要的训练文件。 在我们打卡界面,点击打卡时就是这样的。加载训练好的东西。然后启动定时器,去获取摄像头信号,然后对比,最终和数据库一致就认为打卡成功。 上面训练部分,其实提供的另一个工程就全部完成了。 这是我们win端界面,圆框就是我们摄像头采集图像显示的位置。 我们需要在Ubuntu下把库全部替换,这样就能编译过了,然后拷贝到开发板上运行。如下: 进来就提示数据库打开失败了,我们这个都是基于数据库,所以还是比较尴尬的,后期的话可以尝试自己全部编译下,然后更新吧。目前就测试,看下效果吧。 使用的硬件增加了一个摄像头。 这是打开摄像头采集的样子。 这个GIF展示了我们的人脸检测情况。 由于没有数据库,只能打印一些信息。当两个数据相等时就进入下一步,判断打卡了。由于没有数据库,就展示下电脑端的效果吧。 想要了解优秀测评者“流行科技”关于MYD-J8MPQC开发板测评原文的可以复制下方链接查看: //bbs.eeworld.com.cn/thread-1199387-1-1.html 想要了解米尔iMX8M Plus开发板可以去米尔官网查看具体的产品介绍: http://www.myir-tech.com/product/myd-jx8mpq.htm












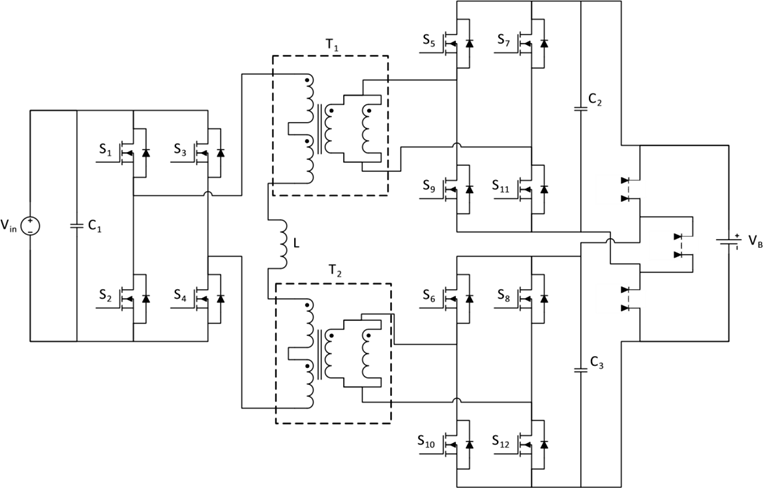
碳化硅(SiC)功率器件正以颠覆性优势引领工业充电器变革——其超快开关速度与超低损耗特性,驱动功率密度实现跨越式提升,同时解锁了传统IGBT无法企及的新型拓扑架构。面对工业应用对高效隔离式DC-DC转换的严苛需求,本文将深入解析从600W至深入解析从600W至30kW全功率段的拓扑选型策略,揭示SiC技术如何成为高功率密度设计的核心引擎。

在汽车电子智能化、网联化与电动化深度融合的浪潮中,车载时钟系统的精度与可靠性正成为决定整车性能的核心命脉。作为电子架构的"精准心跳之源",车规级晶振的选型直接影响ADAS感知、实时通信、动力控制等关键功能的稳定性。面对严苛路况、极端温差及十年以上的生命周期挑战,工程师亟需兼具高稳定性与强抗干扰能力的时钟解决方案——小扬科技将聚焦车规级晶体/晶振核心参数,3分钟助您精准锁定最优型号。
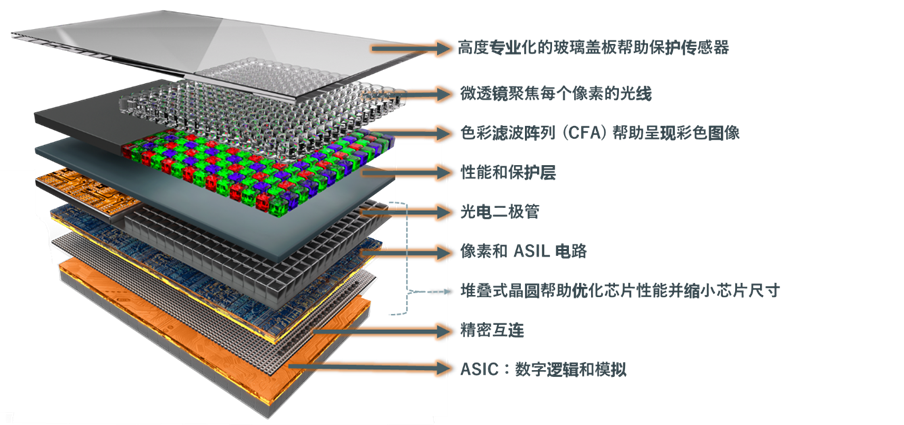
在技术创新的浪潮中,图像传感器的选型是设计与开发各类设备(涵盖专业与家庭安防系统、机器人、条码扫描仪、工厂自动化、设备检测、汽车等)过程中的关键环节。选择最适配的图像传感器需要对众多标准进行复杂的综合评估,每个标准都直接影响最终产品的性能和功能。从光学格式(Optical Format)和动态范围(Dynamic Range),到色彩滤波阵列(CFA)、像素类型、功耗及特性集成,这些考量因素多样且相互交织、错综复杂。
压控晶振(VCXO)作为频率调控的核心器件,已从基础时钟源升级为智能系统的"频率舵手"。通过变容二极管与石英晶体的精密耦合,实现电压-频率的线性转换,其相位噪声控制突破-160dBc/Hz@1kHz,抖动进入亚纳秒时代(0.15ps)。在5G-A/6G预研、224G光通信及自动驾驶多传感器同步场景中,VCXO正经历微型化(2016封装)、多协议兼容(LVDS/HCSL/CML集成)及温漂补偿算法的三重技术迭代。

在电子设备的精密计时体系中,晶体振荡器与实时时钟芯片如同时间系统的"心脏"与"大脑":晶振通过石英晶体的压电效应产生基础频率脉冲,为系统注入精准的"生命节拍";而实时时钟芯片则承担时序调度中枢的角色,将原始频率转化为可追踪的年月日时分秒,并实现闹钟、断电计时等高级功能。二者协同构建现代电子设备的"时间维度"。



