发布时间:2021-06-21 阅读量:3864 来源: 机器之心 发布人: Joisse
2080Ti竟然可以当V100来用,这个功能有点儿厉害。
自深度学习大潮兴起,模型就朝着越来越大、越来越「深」的方向发展。
2012年,拥有5个卷积层的AlexNet第一次在视觉任务上展现出强大的能力。在此之后,基础模型就开始「深」化起来:2014年的VGG-Net达到了19层;2015年的ResNet、2017年的DenseNet更是将深度提升到了上百层。
模型大小的提升极大地提高了性能。因此,各大视觉任务都将ResNet、DenseNet等当做基本的BackBone。但与此同时,模型的增大也意味着对显存的需求随之变高。
为什么GPU显存如此重要?
九年前,Hinton等人率先用两张3GB显存的GTX580GPU高效训练AlexNet。在此之后,显存需求与模型大小就一直同步增长。打比赛想要取到好成绩、做实验想要超越Stateoftheart效果、做工程想要拟合庞大的业务数据等等,这些都离不开显存的加持。
模型加一层,显存涨一分
在深度学习模型中,占用显存的总是那些特别大的张量,比如各层的权重矩阵、计算出来的张量(激活值)、反向传播需要的张量等。在视觉任务中,占据绝大多数的是中间计算出来的张量。随着模型变得更深更大,每一层的激活值张量都需要保留在显存中。
以ResNet50为例,在模型的训练中,前向传播中50层的计算结果都需要保存在显存中,以便让反向传播利用这些张量计算梯度。如果使用ResNet108,需要的显存就会比ResNet50多出一倍多。显存的增加,带来的当然是模型效果的提升。另一方面,如果显存不够,许多工作也必将无法实现。
显存不够,写论文、打比赛屡遭掣肘
在实验室跑模型、写论文的过程中,显存不够用也是常有的事。一般实验室的显卡都是大家共用的,可能分配到每个人的手上已经所剩无几。甚至于,随着顶尖模型越来越大,所有人都没有足够的算力、显存去复现终极实验,更不用说超越其SOTA结果。
遇到这种情况,学生无非只有两种选择:向导师申请新的GPU资源,或者缩减模型做一个Mini版的实验。前者并不总是能够成功,后者则可能会有种种不完美。如果能用有限的显存跑顶尖的大模型,做实验、写论文都会变得更加简单。
此外,无论是在学校还是在公司打比赛,算力不够、显存不足都是常有的事。顶尖竞争者的模型结构可能相差无几,区别就在于谁的模型更大、更有能力去处理复杂的样本。更直观地说,排行榜领先者的模型也许就只差十几层,但也正是因为显存受限少了那十几层,有些模型才与冠军失之交臂。
显存:约束算法工程师的瓶颈
再举一个常见的例子,企业中的算法工程师拥有足够的算力,显存没那么重要。然而,只使用并行策略分担显存,还是可能会出现显存足够、但每张GPU的计算负载又不足的情况。

图:4张V100,显存占满,而GPU利用率很低
即使是V100这样强大的算力,训练大模型时也很容易占满16GB显存。然而由于批量不够大,上图每张V100GPU的利用率只有20%到30%。只有继续增大每次迭代的数据吞吐量,才能增加GPU的利用率。
MegEngine:显存需要优化
其实对于深度学习从业者来说,日常应用中出现的情况远不止上面三种。做深度学习,不论是研究还是工程,时不时就会遇到显存问题。但这个问题优化起来又很复杂,需要利用大量的工程实现来缓解。显然,这样的优化应该由深度学习框架来完成。不过,在实际应用中不难发现,TensorFlow、PyTorch似乎都没有提供完善的官方解决方案。
但如果把目光投向新生势力,情况可能就不一样了。在旷视开源深度学习框架MegEngine最近发布的1.4版本中,该框架首次引入了动态图显存优化技术,大大降低了显存占用问题。
具体来说,通过复现并优化ICLR2021Spotlight论文《DynamicTensorRematerialization》(以下简称DTR),MegEngine实现了「用计算换取更多显存」。有了这项技术的加持,模型的显存占用大大降低,同样的硬件可以训练更大的模型、承载更大的BatchSize。如此一来,学生的小显卡也能开始训练大模型,而工程师们的服务器也经得起更充分的应用。

图:原本需要16GB显存的模型,优化后使用的显存峰值就降到了4GB
MegEngine这种显存优化技术,让1060这样的入门级显卡也能训练原本2080Ti才能加载得上的模型;而11GB显存的2080Ti,更能挑战原本32GBV100才能训练的模型。要知道,V100的价格可是2080Ti的9倍还多。
两行代码,显存「翻倍」
如要需要自己去优化显存,可能99%的算法工程师都会放弃。最好的办法是告诉深度学习框架,这次训练就分配多少显存,剩下的就交给框架自己去优化。MegEngine的动态图显存优化就是基于这一逻辑。
通过两行代码,框架可以全自动地完成显存优化,将所有优化逻辑与复杂的工程实现都隐藏在MegEngine内部。

如上图所示,在动态计算图中导入DTR显存优化模块,并配置显存释放阈值为5GB。训练时,因为显存已经「翻倍」了,BatchSize翻四倍也能装到GPU中。
显存扩增带来的收益
很多时候,提高显存的利用率,最显著的作用就是能训练更大的模型。从一定程度上来说,参数量越大就意味着效果越好;而批大小越大,梯度更新方向就越准确,模型性能也就越优异。MegEngine开发团队做了很多实验,以确保提高显存利用率的同时训练是优质的。
最简单的验证方法就是不断增加批大小,看看显卡到底能坚持到什么程度。下面两张表分别展示了在PyTorch及MegEngine上加载或不加载动态图显存优化(DTR)技术的效果。

如果不使用动态图显存优化技术,PyTorch上的模型一次训练迭代最多只能处理64个样本,MegEngine能处理100个样本。只要加上DTR,PyTorch模型一次迭代就能处理140个样本,MegEngine能尝试处理300个样本。
如果换算成模型大小,加上动态图显存优化技术的MegEngine,在相同的GPU及批大小情况下,能高效训练增大近乎5倍的模型。
MegEngine动态图显存优化技术
深度学习模型的显存占用一般分为权重矩阵、前向传播的中间张量、反向传播的梯度矩阵(Adam优化器)三部分。
权重矩阵和梯度矩阵占的内存很难优化,各个模型基本上都有一个定值。前向传播的中间计算结果则不然:随着BatchSize的增加以及模型层和数量的增加,显存必然跟着增加。如果模型比较大,中间计算结果将占据最主要的显存。

如上图所示,在前向传播中(第一行从左到右),蓝色圆圈表示模型的中间计算结果开始占用显存。一直到前向传播完成,第一行完全变为蓝色圆圈,前面计算所占用的显存都不能释放。
等到反向传播开始(第二行从右到左),随着梯度的计算与完成应用,前向传播保留在显存中的张量才可以释放。
很明显,如果要降低显存占用,就要拿前向传播保存的中间计算结果开刀,这也正是MegEngine动态图显存优化的主要方向。
用计算换显存
对于动态计算图,最直接的方法就是用计算或内存换显存。因此,MegEngine首先要决定到底使用哪种技术。
MegEngine团队通过实验发现,用计算耗时远比交换耗时少。例如从显存中节省612.5MB空间,用带宽换显存要比用计算换显存慢了几十上百倍。

图:因此很明确,动态计算图中也应该使用梯度检查点技术,用计算换显存
如下为梯度检查点技术原理示意,前向传播中第三个点为检查点,它会一直保存在显存中。第四个点在完成计算后即可释放显存,在反向传播中如果需要第四个点的值,可以从第三个点重新计算出第四个点的值。

虽然大致原理不难理解,但具体怎么做还是比较复杂的,MegEngine团队借鉴了论文《DynamicTensorRematerialization》,将其优化并实现到MegEngine中。
DTR,最前沿的显存优化技术
DTR是一种完全动态的启发式策略,核心思想是当显存超过某个阈值时,动态地释放一些合适的张量,直到显存低于阈值。一般而言,释放张量的标准有三个:重新计算出该张量的开销越小越好;占用的显存越大越好;在显存中停留的时间越长越好。

除去从检查点恢复前向传播结果张量带来的主要开销,DTR的额外开销在于寻找应该被释放的最优张量,即计算上图张量t的f(t)值。为了降低这一部分的计算量,MegEngine还采用了两种运行时优化:
不考虑小的张量,它们不加入候选集
每次在需要释放张量的时候,随机采样并遍历少部分张量,以节省计算开销
最难的是工程实现
虽然DTR看上去原理也不复杂,但真正的难题在于提高易用性,即将所有细节都隐藏到框架的底层,只为开发者提供最简单的接口。
在此就用一个最简单的计算例子,跟着框架演算一遍,看看MegEngine是如何利用动态图的计算历史恢复与释放张量的。

现在假设输入有a和b两个张量,并希望计算a*b与a+b,但是显存最大只能保存三个张量。在黄框计算c=a+b时,显存还能保留张量c,然而在下一步绿框计算d=a*b时只能先释放c才能保存d。
不巧的是,下一步灰框需要获取黄框的计算结果,然而为了节省显存,c已经被释放了。所以,MegEngine现在需要做的是重新运行灰框的计算图,计算c=a+b,并加载到显存中。显然,这样做必然需要释放d的显存。
这样一来,鉴于显存的限制,MegEngine就会自动选择合适的张量释放,并在需要时重新计算。如果需要重新计算某个张量的结果,例如上图的d,就需要具体的历史计算信息(在这里就是a+b这样的计算路径),与此同时还需要知道a和b这两个输入张量。
所有这样的历史计算信息都由MegEngine自动获取与保存,MegEngine的工程师已经在底层用C++处理完毕,用户完全不需要考虑。
1 structComputePath{
2 std::shared_ptr<OpDef>op;
3 SmallVector<TensorInfo*>inputs;
4 SmallVector<TensorInfo*>outputs;
5 doublecompute_time=0;
6 }*producer;
7 SmallVector<ComputePath*>users;
8 size_tref_cnt=0;
以上为MegEngine底层用于追踪计算路径信息的结构体。其中op表示产生该张量的算子;inputs和outputs分别表示这个算子需要的输入与输出张量;compute_time表示该算子实际的运行时间。
实际上,在使用MegEngine的过程中,全都是用Python接口创建张量,只不过框架会对应追踪每个张量的具体信息。每当需要访问张量,不用考虑张量是否在显存中时,没有也能立刻恢复出来。所有这些复杂的工程化的操作与运算逻辑都隐藏在了MegEngineC++底层。

图:Python代码会翻译成C++底层实现,C++代码会通过指针管理显卡内存中真正的张量(右图绿色部分)
幸好这样的复杂操作不需要算法工程师完成,都交给MegEngine好了。
MegEngine能做的事情远不止于此,只不过大多是像动态图显存优化这种技术一样,润物细无声地把用户的实际问题解决于无形。2020年3月开源的MegEngine在以肉眼可见的速度快速成长,从静态计算图到动态计算图,再到持续提升的训练能力、移动端推理性能优化、动态显存优化……这也许就是开源的魅力。只有不断优化和创新,才能吸引和满足「挑剔」的开发者。MegEngine下一个推出的功能会是什么?让我们拭目以待。

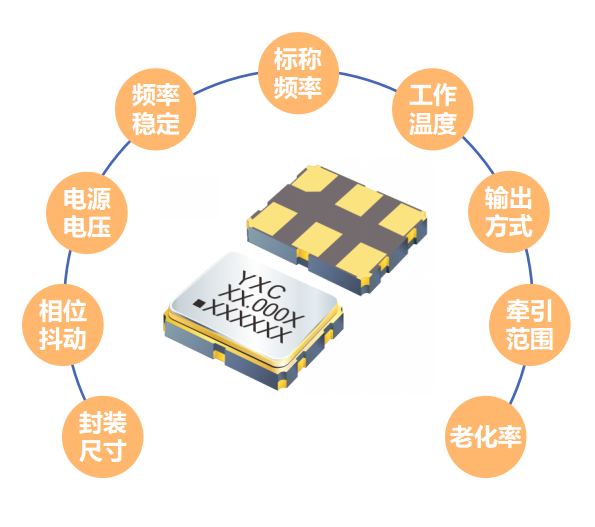
在汽车电子智能化、网联化与电动化深度融合的浪潮中,车载时钟系统的精度与可靠性正成为决定整车性能的核心命脉。作为电子架构的"精准心跳之源",车规级晶振的选型直接影响ADAS感知、实时通信、动力控制等关键功能的稳定性。面对严苛路况、极端温差及十年以上的生命周期挑战,工程师亟需兼具高稳定性与强抗干扰能力的时钟解决方案——小扬科技将聚焦车规级晶体/晶振核心参数,3分钟助您精准锁定最优型号。
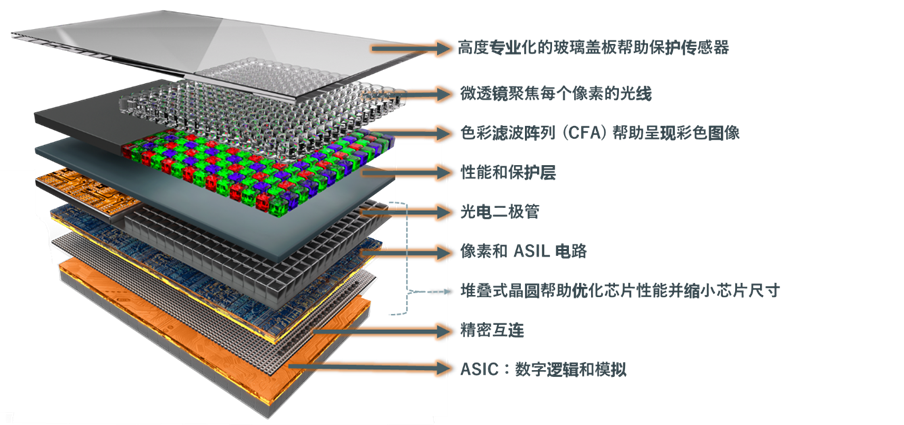
在技术创新的浪潮中,图像传感器的选型是设计与开发各类设备(涵盖专业与家庭安防系统、机器人、条码扫描仪、工厂自动化、设备检测、汽车等)过程中的关键环节。选择最适配的图像传感器需要对众多标准进行复杂的综合评估,每个标准都直接影响最终产品的性能和功能。从光学格式(Optical Format)和动态范围(Dynamic Range),到色彩滤波阵列(CFA)、像素类型、功耗及特性集成,这些考量因素多样且相互交织、错综复杂。
压控晶振(VCXO)作为频率调控的核心器件,已从基础时钟源升级为智能系统的"频率舵手"。通过变容二极管与石英晶体的精密耦合,实现电压-频率的线性转换,其相位噪声控制突破-160dBc/Hz@1kHz,抖动进入亚纳秒时代(0.15ps)。在5G-A/6G预研、224G光通信及自动驾驶多传感器同步场景中,VCXO正经历微型化(2016封装)、多协议兼容(LVDS/HCSL/CML集成)及温漂补偿算法的三重技术迭代。

在电子设备的精密计时体系中,晶体振荡器与实时时钟芯片如同时间系统的"心脏"与"大脑":晶振通过石英晶体的压电效应产生基础频率脉冲,为系统注入精准的"生命节拍";而实时时钟芯片则承担时序调度中枢的角色,将原始频率转化为可追踪的年月日时分秒,并实现闹钟、断电计时等高级功能。二者协同构建现代电子设备的"时间维度"。
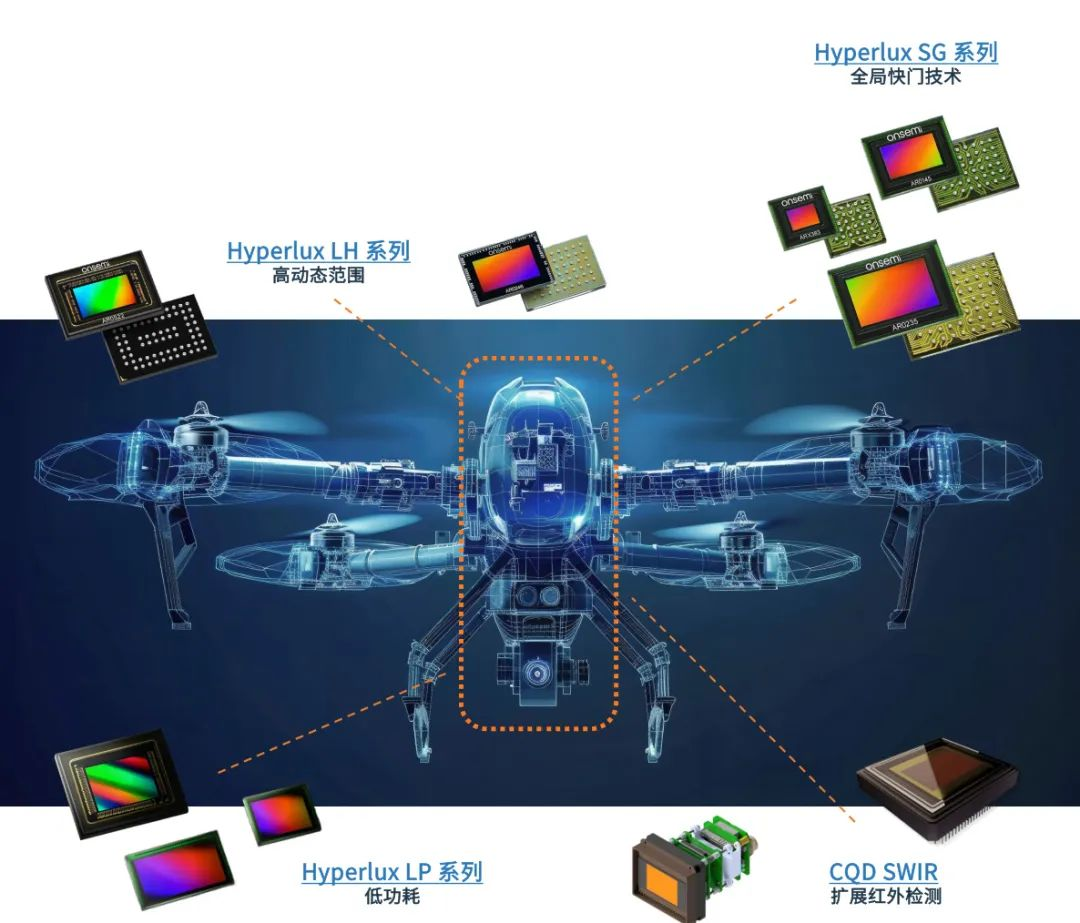
无人机已不再是简单的飞行器,而是集成了尖端感知与决策能力的空中智能载体。其核心系统——特别是自主导航与感知技术——是实现其在测绘、巡检、农业、物流、安防等多个领域高效、精准作业的关键。本文将深入剖析无人机如何通过这些核心技术“看见”、“思考”并“规划”路径,实现真正意义上的自主飞行能力。



