发布时间:2019-08-21 阅读量:883 来源: 智东西 发布人: Jane
芯潮8月20日消息,昨夜,全球有史以来最大的计算机芯片问世!
这款巨型芯片(WSE)来自美国创企Cerebras,每边约22厘米(约8.5英寸),比iPad还要大。
它的具体参数如下:
· 面积46225 平方毫米
· 1.2 万亿个晶体管
· 400000个AI优化核心
· 18 Gigabytes 片上内存
· 9 PByte/s内存带宽
· 100 Pbit/s fabric带宽
· 台积电16nm制程

就是这样一张闪光的厚板,能承载起谷歌等科技巨头所创建的超大规模神经网络所需的并行处理速度。
美媒《连线》直接称赞它为,承载着科技行业对人工智能(AI)希望的纪念碑。
国内外多位芯片专家闻悉此讯,立即在朋友圈发表感慨。
台积电高级副总裁布拉德·保尔森(Brad Paulsen)自20世纪80年代初期,就开始从事半导体行业工作,他说,这是他见过的最大芯片。
国内AI芯片明星创企深鉴科技的创始人姚颂发文称:“Cerebras的Wafer-scale chip确实壮观,有一种独特的美感,就好像看到大炮巨舰的那种壮丽之情。希望Andrew Feldman一切顺利。”
芯片制造商美光的研究员Eugenio Culurciello表示,Cerebras芯片的规模和雄心堪称“疯狂”。
如果不出意外,这款晶圆级引擎(WSE,Wafer Scale Engine)将为AI研究带来前所未有的速度和规模。
一、神秘创企终于出山
过去四年间,人工智能(AI)技术已然风靡科技行业,从语音助手、刷脸支付、智慧安防到自动驾驶,AI的应用愈发广泛。
而训练AI模型需要强大的算力,面对这一广阔的市场,从NVIDIA、英特尔等传统半导体巨头,到各种初创公司,都在竞相开发从根本上改变计算机构建方式的AI芯片。
而Cerebras Systems,正是这场争夺战中,一名低调而又实力强劲的玩家。
Cerebras Systems创办于2016年,据其官网介绍,这家创企现有团队超过150人。
50岁的Andrew Feldman是这家公司的创始人兼CEO。
他曾是小型服务器公司SeaMicro的联合创始人兼CEO,在将SeaMicro以3.34亿美元的价格卖给AMD后,又到AMD做了两年半的副总裁。

▲Cerebras Systems创始人兼CEO Andrew Feldman
AMD的CTO Gary Lauterbach今年63岁,从事芯片工作已有37年,是和Feldman合作了十二年的老伙计。
他也是SeaMicro的联合创始人,后来也同样加入了AMD。在上世纪90年代,Lauterbach还曾担任Sun Microsystems的高级芯片设计师。
自成立以来,Cerebras Systems一直行事十分低调。
当大家还对它要做什么一无所知时,它已经悄然完成三轮融资,筹集1.12亿美元,估值飙升至8.6亿美元。
2016年年中,Cerebras完成第一笔6450万美元的融资;次年1月,经2500万美元的B轮融资后,其估值迅速上升至2.45亿美元;仅6个月后,Cerebras再筹集6000万美元,估值达8.6亿美元。
给它投资的有为Twitter、Snap提供资金的Benchmark,传奇芯片设计师、AMD前CTO Fred Weber、著名非营利实验室OpenAI的AI科学家、AlexNet的联合创建者Ilya Sutskever等业界知名机构或大牛。
现在,这家创企的计划终于浮出水面,他们想将所有数据都保存在一个巨大的芯片上,以便加快系统运行速度,节省数据在芯片之间传递所造成的不必要的消耗。
二、史上最大芯片:比Tesla V100大56倍
目前,深度学习芯片市场绝大多数由NVIDIA GPU主导。
人工智能(AI)的第三次热潮由深度学习引爆,而通用GPU恰恰与深度学习运算天然地契合。
乘着深度学习发展之势,GPU霸主NVIDIA在AI时代迅速崛起,过去五年股价飙升了8倍,成为AI芯片第一股。
在AI训练领域,NVIDIA的旗舰GPU犹如标杆般的存在。
2017年,NVIDIA发布其时史上最强大的“核弹”——旗舰GPU Tesla V100,核心面积达到创纪录的815平方毫米,拥有超过210亿个晶体管。

▲WSE和GPU芯片面积的并排比较
而Cerebras的巨型芯片WSE的面积有46225平方毫米,拥有1.2万亿个晶体管,面积和晶体管数量足足是Tesla V100的56倍有余。
Cerebras创始人兼CEO Andrew Feldman表示,这个巨型处理器可完成数百个GPU的集群工作,具体能完成的量则取决于手头的任务,同时它将消耗更少的能源和空间。
三、三大特征:超强AI算力、高效存储、高带宽通信
Feldman表示,WSE训练AI系统的速度可以比现有硬件快100到1000倍。
1、更强AI算力
WSE包含400000个稀疏线性代数(SLA)内核,每个AI优化核心都是灵活可编程的,并针对支撑大多数神经网络的计算进行了优化。
可编程性确保内核可以在不断变化的机器学习领域中运行所有算法。
单个芯片上即具群集规模的资源,可以任何批量大小下完全利用,用以提供更快的AI训练速度。
2、高带宽、低延迟通信结构
WSE上的400000个内核,通过Swarm通信结构连接在一个带有100 Pb/s带宽的2D网格中。
Swarm是一种巨大的片上通信结构,可提供突破性带宽和低延迟,而功耗仅为用于集成图形处理单元的传统技术的一小部分。
它完全可配置; 软件配置WSE上的所有内核,以支持训练用户指定模型所需的精确通信。
对于每个神经网络,Swarm提供独特且优化的通信路径。
3、高效高性能的片上存储
WSE具有18 GB的片上存储器,可在单个时钟周期内访问,并提供9 PB/s的存储器带宽。
它的容量是NVIDIA Tesla V100的3000倍,带宽是Tesla V100的10000倍。
更多内核、更多本地内存可实现快速灵活的计算、更低的延迟和更少的能耗。
四、巨芯是如何制成的?
为了节省数据在芯片之间传递所造成的时间、功耗浪费,设计一颗能实现超强计算能力的AI芯片,Cerebras的解决方案是能做多大做多大。
而最大的芯片,自然就是从能找到的最大的晶圆中切出的“拿出能找到的最大的晶圆并从中切出最大的裸片。
要做到这一点,必然要打破很多规则,也必须面临设计、良率、冗余、封装、散热、供电等多方面的挑战。
1、自研设计软件工具
芯片设计人员是用Cadence、新思科技等公司的芯片设计软件来规划晶体管的排列。
但传统芯片仅有数十亿个晶体管,而Cerebras芯片的晶体管有1.2万亿,这是一般的芯片设计工具无法实现的。
因此,Cerebras建立了自己的设计软件工具。
2、建立冗余,绕过缺陷
为了构建其巨型芯片,Cerebras与其合约芯片制造商台积电(TSMC)密切合作。
现代晶圆代工厂常用直径约300毫米、约12英寸的晶圆,通过将网格放置在晶片上进行切割,这种晶圆片通常能产生超过100个芯片。
但做巨型芯片是不同的,台积电高级副总裁Brad Paulsen表示,台积电调整其设备以进行一次连续设计,而不是多个独立设计的网格,从而从300毫米的晶圆上,切割下来一个最大的正方形来做芯片。
上世纪七八十年代就开始有一些人尝试这样做,比较著名的是一家Trilogy的创企,由IBM芯片工程师Gene Amdahl于1980年创立,当时拿到超过2.3亿美元的资金支持,但后来因为难度太高,这项任务五年后已经中止。
若论将硅晶片大小的芯片从实验室搬到商业应用,Cerebras大概是第一个。
当蚀刻电路时,晶圆会产生一些无法修复的缺陷区域。在同样的缺陷分布下,晶圆分割的数量越少,裸片越大,缺陷的影响就越大,
NVIDIA、英特尔等研制小型芯片的厂商可以通过削减晶圆中的优质芯片、废弃其余芯片,来解决这一问题。
但有整个晶圆那么大的芯片,显然不能这样做。
毕竟晶圆上只有一块芯片,假使晶圆上有bug,那芯片受影响的几率等于100%。
为了尽量减少晶圆缺陷的影响,Cerebras必须建立冗余电路、绕过缺陷,保证其就像个人服务器计算机出故障时仍能继续运行的微型互联网,保持能提供40万个工作核心的状态。
3、复杂水冷系统,芯片不单销
制造如此强大的芯片,还要面临散热的难题。
Feldman表示,其芯片不会单独销售,而是将被打包到围绕芯片构建的完整服务器中。
Brad Paulsen认为,这么大的芯片也会消耗大量功率,这意味着保持冷却将会困难且昂贵,这个过程“需要更多劳动力”。
保持数据中心工作温度对大多数据中心而言是一个挑战,但Cerebras必须设计一个复杂的水冷系统,靠近芯片,可以抵消以15千瓦功率运行的芯片产生的极端热量,以防止芯片过热。
“你不能用设计插入任何旧戴尔服务器的芯片来做到这一点,”这是Feldman的理念,“如果你制造一辆法拉利发动机,那么你想建立整个法拉利。”
据他估计,他的计算机将是内置多个NVIDIA芯片的服务器的150倍,而功耗只是服务器机架所需物理空间的一小部分。
他预测,在云计算设施中运行成本高达数万美元的AI训练任务,有望将成本降低一个数量级。
五、巨芯的商用价值有几何?
据悉,少数客户将在9月份开始尝试WSE芯片。
不过,关于芯片的成本、售价以及实用性,Feldman还没有给出相关回应。
尽管WSE的算力、存储和通信能力听起来都很惊人,但它在商业应用上的可行性还存在“问号”。
一个明显的问题就是用户习惯。
以包含特殊水冷系统的精密设备为例,它与多数大型科技公司以及政府的使用习惯完全不同。
英特尔副总裁Naveen Rao表示,非常规形状的芯片在销售时会相对“艰难”,因为客户不喜欢放弃他们现有的硬件。
他认为:“为了改变这个行业,我们必须以增量方式实现这一目标。”
Tirias Research的创始人Jim McGregor也认同这一观点,并非所有科技公司都会急于购买像Cerebras这样异类的芯片。
成本方面,McGregor估计Cerebras的系统可能需要花费数百万美元,而现有的数据中心可能需要进行修改以适应它们。
另外,Cerebras还必须开发软件,以使AI开发人员能够轻松适应新芯片。
当前Cerebras的软件堆栈已与开源机器学习框架TensorFlow、PyTorch集成,软件使用当今的工具为用户提供集群规模的计算资源。
结语:落地有待观察,尝试振奋人心
由于Cerebras尚未披露关于性能的统计数据,虽然Feldman称有些人已经收到原型,结果将训练时间从几个月缩短到几分钟,但分析师Gwennap认为,在看到基准测试之前,很难评估AI的设计有多好。
另外,Cerebras如何让40万个内核高效协同仍有待观察,毕竟编程这么大的设备,如何有效分配任务是个相当有挑战的工作。
不过,从结果来看,Cerebras做了相当振奋人心的尝试,不仅打造了新颖品类的AI计算机,也创造了制造晶圆级芯片的设计平台。
传奇芯片设计师Weber认为,如果Cerebras想为其他公司设计芯片,这一成就本身就能达到10亿美元。
在他看来,Cerebras这一家公司就创造了两个硅谷“独角兽”。
Feldman对未来相当抱有信心,他认为在大数据时代,要处理的数据量海量增长,但在性能改进方面,NVIDIA和英特尔的进展将放缓。
因此Feldman预计,未来几年AI将占据所有计算活动的三分之一。如果他是对的,就像电影“大白鲨”一样,整个世界都需要更大的船。
文章来源:Fortune,Wired,The New York Times
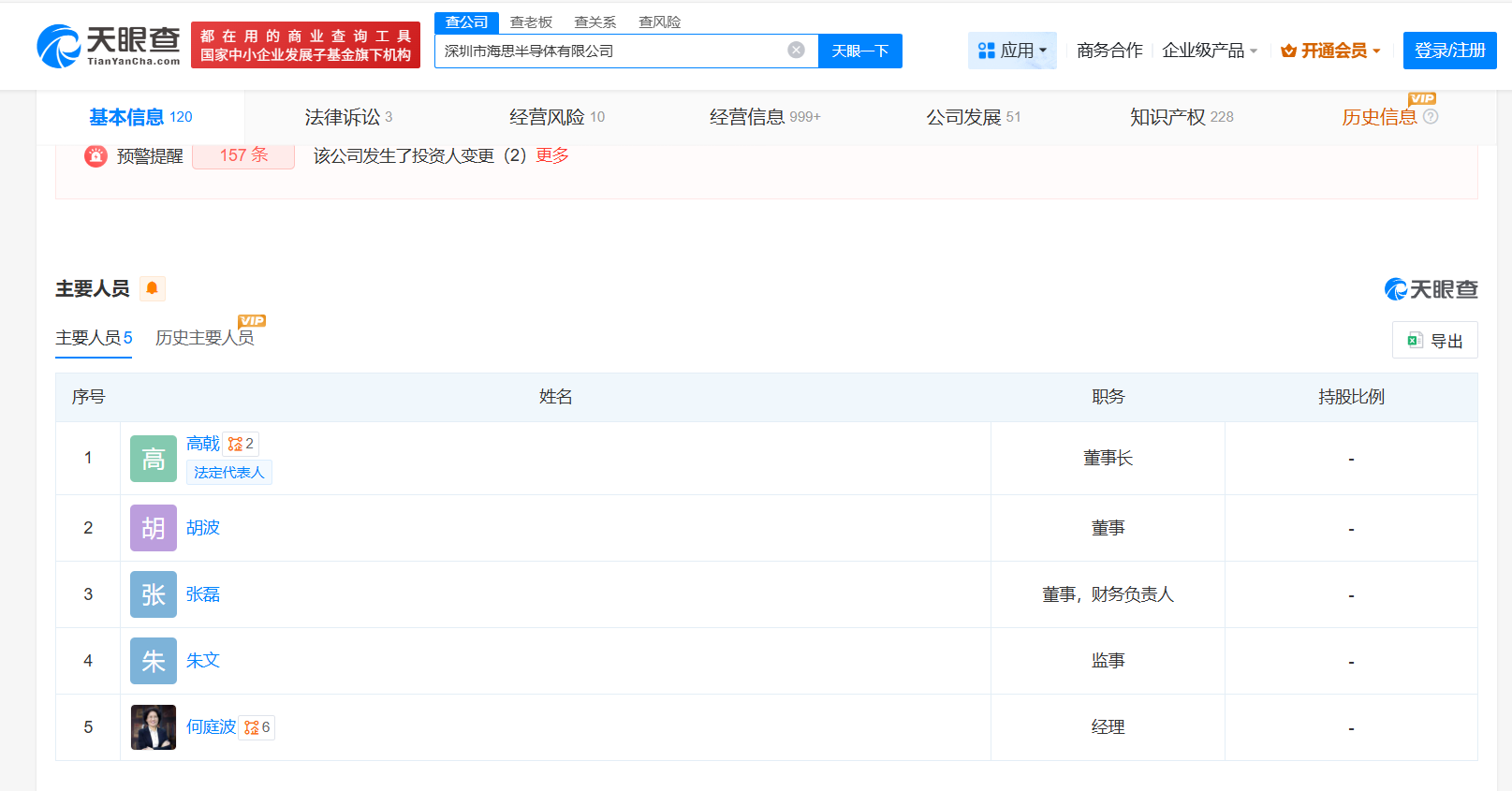
华为旗下核心芯片设计公司深圳市海思半导体有限公司完成重大人事调整,徐直军卸任法定代表人、董事长,由技术背景深厚的高戟接棒,同时完成多位高管的更迭

美国联邦通信委员会(FCC)发布通告:“基于国家安全考量”,FCC即刻实施新规,撤销或拒绝由“外国对手”控制的测试实验室的FCC认证资格

为精准锚定行业需求、高效整合产业资源,全力备战2025年11月5–7日在上海新国际博览中心举办的第106届中国电子展,中国电子展组委会与电子制造产业联盟联合组建专项调研团队,于近期跨越广东、湖南、湖北三省,深入深圳、东莞、长沙、武汉四地,开展了一系列高密度、深层次的企业走访与产业对接活动。通过实地考察和多轮座谈,调研团队系统梳理了华南、华中地区电子制造产业链资源,为展会的高水平举办奠定了扎实基础。

Type 2FR模块可以为智能家居、工业自动化、游戏控制器和智能配件应用提供出色的集成度、效率和多种无线电功能

英飞凌XENSIV™ PAS CO2 5V传感器可持续提供高质量数据,并且满足WELL™建筑标准的性能要求。



